Take a moment to go back in time with me, back to when life was simpler and the biggest threat to humanity was Y2k…
It is 1999, you’re 13, and your mother just walked through the front door carrying a large, vibrantly colored blue and yellow bag. Based on the heft and the "Best Buy" logo on the side, you know it holds something interesting—something related to electronics—but what? A Nintendo 64? A Dell computer? 1,000 free hours of AOL?
There is only one way to find out.
Depending on your maturity and cowhand status you walk, mosey, or scamper up to take the bag. In a single, excited motion you reveal a nondescript cardboard box. It has no clear branding, just three letters: "DVR". On the opposite face, an illustrated TV depicting endless suited silhouettes.
"This is going to change everything." She says calmly, looking you in the eyes. You nod, and set it up.
A few moments later you are both sitting on the floor staring at… Al Gore. He is talking about a lock box. The screen fades, and George Bush appears. This continues for hours. Political ad after political ad. No interruptions. For days. For years.
In fact, you are still watching now.
Presenting the Political Ad Archive
Oh ***.
Witness the Internet Archive's Political Ad Archive. Our mission is to provide a free and open resource for citizens, journalists, and researchers who want to understand the paid messages from their politicians, and to archive billions of dollars worth of democracy.
We record and track political ads. Through our service you can find out when, where, and how often a given ad was played across the channels we are recording. It also tells you who the ads are about, who paid for them, what is said in them, whether they have been fact checked, and plenty of other odds and ends.
This post is about how the service works, but I'll start with the punch line: we watch tons of TV—probably literally, our servers are heavy—and filter out the noise, leaving only the political ads. Then our DVR robots (DVRRs for short) activate and count all copies of those ads, keep track of when and where they were played, toss in a little human contributed metadata, and share the DVRR results (DVRRRs) and code base with you, our DVRRR recipients.
Three key pieces
There are three pieces to the Political Ad Archive:
- The Internet Archive collects, prepares, and serves the TV content as it comes. It’s trying to archive the entire internet too, so their infrastructure is set up to be able to store, you know, all of human knowledge.
- The Duplitron 5000 is an open source system responsible for taking video, smooshing it all into smaller, searchable files called audio fingerprints, and then finding copies of known ads. It reports the results back to the archive.
- The Political Ad Archive is a wordpress site that takes our data and our videos and presents it to the rest of the world.
Look, here’s a fun flow chart of the entire process:
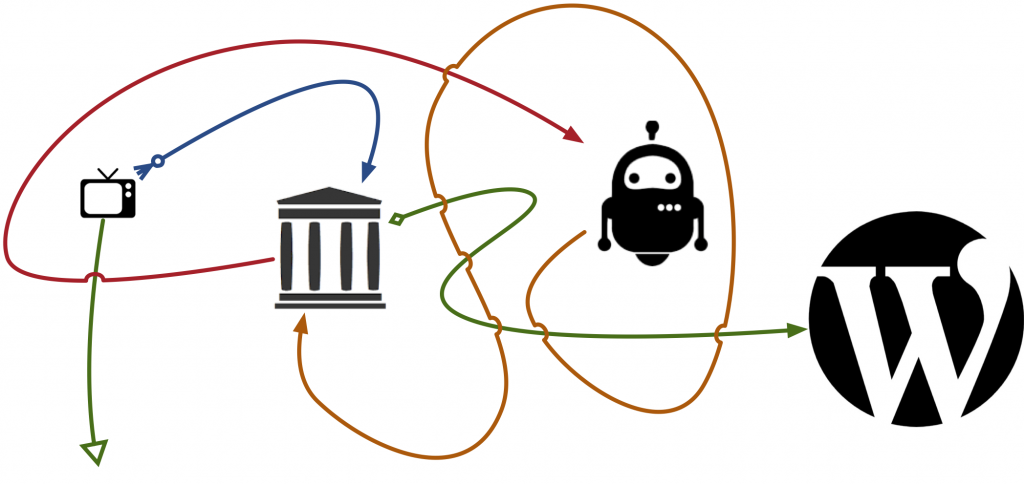
Step 1: Recording Television
All of our artisanal grass-fed TV has been locally sourced from super-premium, organic hardware distributed around the country. We do process it though. A lot. Sorry about that.
The ad counts we publish are based on actual airings, as opposed to reported airings. Because we are working from the source, we know we aren’t being misled by anything but our own algorithms. On the flip side this means that we can only report counts for the channels we actively record.
We have a few ways to collect TV content. In some cases, like the San Francisco market, we own and manage the hardware that records local cable. In other cases, like New Hampshire and Philadelphia, the content is provided to us by third party services or academic partners.
Regardless of how we get the data, the pipeline takes it to the same place. We record in minute long chunks of video and stitch them together into programs based on what we know about the station’s schedule. This results in video segments of anywhere from 30 minutes to 12 hours. Those programs are then put into a high pressure cooker and turned into all sorts of file formats for archival purposes (mp3, mp4, MBA, PST, Apollo 13, banana).
A lot can go wrong here. Storms can affect satellite reception, packets can be lost or corrupted before they reach our servers (resulting in time shifts or missing content), small children can disappear in our server rooms. It all happens, but most of the time the data winds up sitting comfortably on our hard drives unscathed.
Step 2: Searching Television…

Illustration by Lyla Duey.
Remember that time you were watching Netflix and you blacked out because your cat sucker-punched you? Wasn’t it a huge pain the next day when you had to try to figure out where you had stopped watching? You kept clicking, waiting for it to buffer, being too early, then too late, then closer but too early, then somehow back to the first try, until you finally gave up and just started from the beginning again?
This is a great example of how terrible video is when you’re trying to look for a specific piece of it. It’s slow, it’s heavy, it is far better suited for watching than for working with.
What if you had no choice, and you really did need to search video for something. Worse, maybe you have to search millions of minutes of video for an arbitrary number of somethings. Welcome to my world.
There are a few things to try. One is transcription; if you have a transcript you can do anything. Like create a text editor for video, or search for key phrases, like “I approve this message.”
The problem is that most television is not transcribed. Closed Captions exist sometimes, but there is a shocking amount of content—especially political ads—without captions. There are a few open source tools out there for automated transcript generation, but the results usually “love match Tobey desert ire” (… leave much to be desired).
So what do we do? Our nation’s future is at stake and we don’t have time to be able to do it all manually. Say hello to audio fingerprinting.
… Using Audio Fingerprinting …
We use a free and open tool called audfprint to convert our audio files into audio fingerprints. An audio fingerprint of a file is just what it sounds like. Get it? AUDIO fingerprint… SOUNDS like? Ha!
An audio fingerprint is a summarized version of an audio file, one that has removed everything except the most interesting pieces of every few milliseconds. The trick is that the summaries are formed in a way that makes it easy to compare them, and because they are summaries they’re a lot smaller and faster to work with than the original.
“Summary” is a pretty vague term. There are lots of ways you can summarize a piece of audio. For instance, I could summarize a song in terms of its chord progression (G major -> C minor -> D major …). If I heard the same song twice it would have the same chord progressions both times, so I could flag it as a match and be correct.
But what if two different bands played the same song? Or what if you compared two pop songs? Those would also have the same chord progressions even though they are obviously different audio files. Also what about spoken word? Or long, loud, sensual recordings of fog horns. No chords in either case. This clearly isn’t going to work.
… Based on Frequency
The audio fingerprints we use are based on a thing called frequency. Sounds are made up of waves, and each wave repeats (oscillates) at different rates. Faster repetitions are linked to higher sounds, lower repetitions are lower sounds.
Don’t believe me? Go drop a small pebble in a lake and you will see a bunch of quickly repeating tiny ripples. Next drop a boulder and you will see a few larger ripples. There are also sounds generated in both cases. The boulder creates a loud and deep “KERPLUNK” — the ripples have a lot of space between them less often, which is true of the ripples through the air as well. The pebble has a lot more ripples closer together which results in a higher pitched “pleep!” How cute!
That number of waves you see can be measured in terms of frequency—as in how frequently does the wave repeat per second. Most sounds you hear are a crazy combination of thousands of waves of different frequencies. Each of the waves get turned into vibrations in your ear that travel down a magical cone covered in tiny hairs which then turns into electric signals to your brain which you then hear in your head as sound. For instance, most people hear an “A” when a wave that repeats 440 times per second (440 Hz) hits our ear drum.

Try waving your hand 440 times per second. If you do, you will hear that “A.”
Computers don’t have ears, so they just take these frequencies at face value. An audio file contains instructions that tell a computer how far to push the inside of a speaker in or out (generating a wave). Audfprint breaks those audio files into tiny chunks (around 20 chunks per second) and runs a mathematical function on each fragment to identify the most prominent waves and their corresponding frequencies.
The rest is thrown out, the summaries are stored, and the result is an audio fingerprint.
If the same sound exists across two files (not the same song, or the same words, or same voice, but literally the exact same set of frequencies), a common set of dominant frequencies will be seen in both fingerprints. Audfprint makes it possible to compare the chunks between two sound files, count how many they have in common, and how many appear in roughly the same distance from one another.
This is what we use to find copies of political ads.
Step 3: Cataloguing Political Ads
When we discover a new political ad the first thing we do is register it on the Internet Archive, kicking off the ingestion process. The person who found it types in some basic information such as who the ad mentions, who paid for it, and what topics are discussed. This is all called metadata.
The ad is then sent to the system we built to manage our fingerprinting workflow, called the Duplitron 5000—known locally as “DT5k”. This uses audfprint to generate fingerprints, organizes how the fingerprints are stored, process the comparison results, and allows us to scale to process across millions of minutes of television.

An artistic rendition of the Duplitron 5000 (by Lyla Duey).
DT5k generates a fingerprint for our new ad, stores it in the list of known political ads, and then compares that fingerprint with hundreds of thousands of existing fingerprints for the shows we have already ingested into the system. It takes a few hours for all of the results to come in. When they do, the Duplitron makes sense of the numbers and tells the archive which programs contain copies of the ad and what time the ad played.
All of these steps end up being pretty darn accurate, but not perfect. The matches are based on audio, not video, which means we face trouble when the same soundtrack is used in a political ad as has been used in, for instance, an infomercial.
We are working on improving the system to filter out these kinds of mistakes, but even with no changes these fingerprints have given us reasonable accuracy across the markets we track.
Step 4: Enjoying the Results
And so you understand the fundamentals behind the amazing futuristic technology that we used to build a system that records only political ads. You can download our data, and watch the ads, all day every day at the Political Ad Archive.
Over the coming months we are working to make the system more accurate, and exploring ways to get it so that it can automagically identify newly released political ads without any need for manual entry.
P.S. we’re also working to make it as easy as possible for random strangers to download all of our fingerprints to use in their own local copies of the Duplitron 5000. Would you like to be a random stranger? If so, contact me on Twitter at @slifty.